Künstliche Intelligenz & Daten
Data & Artificial Intelligence Solutions
Erleben Sie, wie KI-gestützte Analysen und fortschrittliche statistische Methoden Ihrem Unternehmen echte Wettbewerbsvorteile verschaffen. Gewinnen Sie tiefgehende Einblicke in das Verhalten Ihrer Kunden, steigern Sie die Effizienz Ihrer Prozesse und messen Sie die tatsächlichen Geschäftsauswirkungen.
In einer sich ständig verändernden digitalen Welt ist der strategische Einsatz von KI und Daten der Schlüssel zum nachhaltigen Erfolg.
Daten werden erst dann wertvoll, wenn sie verständlich, nutzbar und in konkrete Entscheidungen übersetzt werden. Ancud IT unterstützt Unternehmen dabei, Datenquellen zu strukturieren, Machine-Learning-Modelle zu entwickeln und KI-Lösungen in bestehende Prozesse zu integrieren.
Ob Data Engineering, Business Intelligence, CRISP-ML oder KI-Datenanalyse: Wir verbinden technologische Kompetenz mit einem klaren Blick auf Geschäftsziele, Datenqualität und messbare Wirkung.

Weiterlesen
Künstliche Intelligenz und Daten als Grundlage digitaler Wertschöpfung
Künstliche Intelligenz entfaltet ihren echten Nutzen erst dann, wenn sie auf belastbaren Daten, klaren Prozessen und einer passenden technischen Architektur aufbaut. Viele Unternehmen verfügen bereits über große Mengen an Daten, können diese aber nur eingeschränkt nutzen. Informationen liegen in verschiedenen Systemen, Datenqualität ist uneinheitlich, Schnittstellen fehlen oder Kennzahlen werden nicht so aufbereitet, dass daraus schnelle und fundierte Entscheidungen entstehen.
Genau hier setzen Data & AI Solutions an. Unternehmen können eine Data-&-AI-Beratung beauftragen, ein konkretes Datenprojekt anfragen oder zunächst einen klar abgegrenzten Analysebaustein bestellen. Es geht nicht nur darum, einzelne Machine-Learning-Modelle zu entwickeln oder moderne KI-Technologien einzusetzen. Entscheidend ist das Zusammenspiel aus Datenstrategie, Data Engineering, statistischer Analyse, Business Intelligence, Modellentwicklung, Qualitätssicherung, Deployment und kontinuierlicher Überwachung. Erst wenn diese Bausteine zusammenpassen, entstehen KI-Lösungen, die im Unternehmen produktiv genutzt werden können.
Künstliche Intelligenz und Daten sind deshalb kein isoliertes IT-Thema. Sie betreffen Geschäftsmodelle, Prozesse, Kundeninteraktionen, Produkte, Services und operative Entscheidungen. Unternehmen, die ihre Daten systematisch nutzen, können schneller reagieren, Risiken besser erkennen, Kundenverhalten genauer verstehen und Prozesse gezielter optimieren.
Warum Datenqualität über den Erfolg von KI entscheidet
Machine-Learning-Modelle sind nur so gut wie die Daten, auf denen sie basieren. Wenn Daten unvollständig, veraltet, widersprüchlich oder schlecht strukturiert sind, entstehen auch bei modernen KI-Verfahren keine verlässlichen Ergebnisse. Deshalb beginnt erfolgreiche KI-Datenanalyse nicht mit dem Modell, sondern mit der Frage, welche Daten vorhanden sind, wie sie entstehen und ob sie für den jeweiligen Anwendungsfall geeignet sind.
Eine belastbare Datengrundlage umfasst mehr als saubere Tabellen. Es geht um Herkunft, Aktualität, Vollständigkeit, Konsistenz, Berechtigungen, Schnittstellen, Datenmodelle und fachliche Bedeutung. Gerade in gewachsenen IT-Landschaften liegen Daten häufig verteilt in ERP-Systemen, CRM-Anwendungen, Fachsoftware, Portalen, Datenbanken, Dokumenten, Ticketsystemen oder externen Quellen. Ohne Data Engineering bleiben diese Informationen oft unverbunden.
Data Engineering schafft die Grundlage, damit Daten für Business Intelligence, Machine Learning und KI-Anwendungen nutzbar werden. Dazu gehören Datenpipelines, Schnittstellen, Datenbereinigung, Transformation, Speicherung und die strukturierte Bereitstellung für Analyse- und Modellierungsprozesse. Erst dadurch können Unternehmen aus Rohdaten belastbare Erkenntnisse gewinnen.
Typische Herausforderungen im Umgang mit Unternehmensdaten sind:
- verteilte Datenquellen ohne gemeinsame Struktur,
- unklare Datenqualität und fehlende Datenverantwortung,
- manuelle Auswertungen in Excel oder isolierten Tools,
- fehlende Schnittstellen zwischen Systemen,
- uneinheitliche Kennzahlen und Definitionen,
- Datenbestände, die für Machine Learning nicht vorbereitet sind,
- fehlende Transparenz über Herkunft und Aussagekraft von Daten.
Wer Künstliche Intelligenz und Daten sinnvoll nutzen möchte, sollte diese Grundlagen zuerst klären. Unternehmen können eine Datenqualitätsanalyse beauftragen, einen Data Readiness Check bestellen oder eine Use-Case- und Datenevaluierung anfragen. Ein gutes KI-Projekt beginnt immer mit einem realistischen Blick auf Datenlage, Datenqualität und fachlichen Nutzen.
CRISP-ML als strukturierter Rahmen für Machine-Learning-Projekte
Machine-Learning-Projekte brauchen Struktur. Ohne klares Vorgehen entstehen schnell technische Experimente, die zwar interessant wirken, aber nicht produktiv einsetzbar sind. CRISP-ML bietet dafür einen methodischen Rahmen. Das Modell hilft, Machine-Learning-Projekte schrittweise zu planen, umzusetzen, zu validieren und in den Betrieb zu überführen.
Im Mittelpunkt steht nicht nur die Entwicklung eines Modells, sondern der gesamte Lebenszyklus einer KI-Lösung. Zuerst wird der Use Case definiert: Welches Problem soll gelöst werden? Welche Daten werden benötigt? Welche fachlichen Erfolgskriterien gelten? Danach folgen Datenevaluierung, Data Engineering, Modellentwicklung, Qualitätssicherung, Deployment sowie Überwachung und Wartung.
Gerade für Unternehmen ist dieser strukturierte Ansatz wichtig. Ein Machine-Learning-Modell muss nicht nur im Test funktionieren, sondern im realen Betrieb stabile, nachvollziehbare und wirtschaftlich sinnvolle Ergebnisse liefern. Dazu gehören klare Messgrößen, regelmäßige Validierung, Monitoring und die Möglichkeit, Modelle bei Bedarf anzupassen.
Ein professioneller CRISP-ML-Prozess berücksichtigt unter anderem:
- fachliche Zieldefinition und Use-Case-Bewertung,
- Prüfung der verfügbaren Daten und Datenqualität,
- Aufbereitung und Strukturierung der Datenbasis,
- Auswahl geeigneter Machine-Learning-Modelle,
- Training, Test und Qualitätssicherung,
- Integration in bestehende Systeme und Prozesse,
- Monitoring der Modellqualität im laufenden Betrieb,
- kontinuierliche Optimierung bei veränderten Daten oder Anforderungen.
So wird aus einer KI-Idee eine produktive Lösung, die technisch belastbar und fachlich sinnvoll ist. Unternehmen können einen CRISP-ML-Workshop beauftragen, einen Proof of Concept anfragen oder ein Machine-Learning-Projekt schrittweise umsetzen lassen.
Data Engineering: Daten nutzbar machen
Data Engineering ist einer der wichtigsten Bausteine für Künstliche Intelligenz und Datenanalyse. Ohne eine stabile Dateninfrastruktur bleiben viele KI-Projekte in der Konzeptphase stecken. Daten müssen gesammelt, bereinigt, transformiert, verbunden und so bereitgestellt werden, dass sie für Analysen, Dashboards und Machine-Learning-Modelle verwendet werden können.
Dabei geht es nicht nur um technische Datenpipelines. Data Engineering verbindet fachliche Anforderungen mit technischer Umsetzung. Welche Daten werden für einen Use Case benötigt? Wie häufig müssen sie aktualisiert werden? Welche Systeme liefern die Informationen? Wie werden Zugriffsrechte berücksichtigt? Welche Formate, Schnittstellen und Speicherstrukturen sind sinnvoll?
Ein gutes Data-Engineering-Konzept sorgt dafür, dass Daten zuverlässig verfügbar sind und nicht jedes Analyseprojekt von vorne beginnen muss. Unternehmen können eine Datenpipeline entwickeln lassen, Data Engineering beauftragen oder die Integration mehrerer Datenquellen umsetzen lassen. Dadurch entsteht eine wiederverwendbare Grundlage für Business Intelligence, KI-Datenanalyse und weitere datengetriebene Anwendungen.
Data Engineering unterstützt Unternehmen zum Beispiel bei:
- Aufbau von Datenpipelines,
- Integration verschiedener Datenquellen,
- Datenbereinigung und Transformation,
- Vorbereitung von Trainingsdaten für Machine Learning,
- Strukturierung von Daten für Business Intelligence,
- Automatisierung wiederkehrender Datenprozesse,
- Bereitstellung von Daten für KI-Anwendungen,
- Schaffung transparenter Datenflüsse.
Damit wird Data Engineering zum Verbindungselement zwischen operativen Systemen, analytischen Anwendungen und produktiven KI-Lösungen.
Business Intelligence: bessere Entscheidungen durch Daten
Business Intelligence hilft Unternehmen, Daten in verständliche Kennzahlen, Reports und Dashboards zu übersetzen. Während Machine Learning stärker auf Vorhersagen, Mustererkennung und automatisierte Analysen ausgerichtet ist, unterstützt Business Intelligence vor allem Transparenz und Entscheidungsfähigkeit im Management und in Fachbereichen.
Ein gutes BI-System beantwortet nicht nur die Frage, was passiert ist, sondern macht Entwicklungen, Abweichungen und Zusammenhänge sichtbar. Unternehmen können Umsatz, Kosten, Prozessleistung, Kundenverhalten, Servicequalität oder operative Effizienz besser verstehen. Dadurch entstehen fundiertere Entscheidungen und ein gemeinsames Verständnis über die wichtigsten Kennzahlen.
Business Intelligence ist besonders wertvoll, wenn Daten aus unterschiedlichen Systemen zusammengeführt werden müssen. Unternehmen können eine BI-Beratung anfragen, ein Dashboard entwickeln lassen oder eine Business-Intelligence-Lösung einführen lassen. Statt isolierter Auswertungen entsteht eine zentrale Sicht auf relevante Informationen. Für viele Unternehmen ist BI deshalb ein wichtiger Schritt auf dem Weg zu datengetriebener Steuerung und später auch zu KI-Anwendungen.
Typische Ziele von Business Intelligence sind:
- Kennzahlen zentral und verständlich darstellen,
- Entscheidungsprozesse beschleunigen,
- manuelle Reporting-Aufwände reduzieren,
- Daten aus verschiedenen Quellen zusammenführen,
- Trends und Abweichungen früh erkennen,
- operative und strategische Steuerung verbessern,
- Grundlage für KI-Datenanalyse und Machine Learning schaffen.
Business Intelligence und Künstliche Intelligenz sollten dabei nicht getrennt betrachtet werden. BI schafft Transparenz, Machine Learning erweitert diese Transparenz um Vorhersagen, Mustererkennung und automatisierte Entscheidungsunterstützung.
Machine-Learning-Modelle für reale Geschäftsprobleme
Machine-Learning-Modelle können Unternehmen helfen, Muster zu erkennen, Vorhersagen zu treffen und komplexe Datenmengen effizient auszuwerten. Der Nutzen entsteht jedoch nicht durch das Modell allein, sondern durch die richtige Verbindung mit einem konkreten Geschäftsproblem.
Ein Machine-Learning-Modell kann zum Beispiel Kundenverhalten analysieren, Nachfrage prognostizieren, Anomalien erkennen, Qualitätsprobleme identifizieren, Dokumente klassifizieren, Prozesse bewerten oder Entscheidungen vorbereiten. Wichtig ist, dass der Use Case klar definiert ist und die Ergebnisse im Unternehmen tatsächlich genutzt werden können.
Nicht jedes Problem braucht ein komplexes Modell. Manchmal reichen statistische Analysen, regelbasierte Logik oder Business-Intelligence-Auswertungen. In anderen Fällen können Unternehmen ein Machine-Learning-Modell entwickeln lassen, die Modellentwicklung beauftragen oder ein konkretes Predictive-Analytics-Projekt anfragen. Eine professionelle Bewertung hilft, den richtigen Ansatz zu wählen und technische Komplexität nur dort einzusetzen, wo sie wirklich Nutzen schafft.
Geeignete Einsatzbereiche für Machine Learning sind unter anderem:
- Prognosen und Forecasting,
- Kundensegmentierung,
- Anomalieerkennung,
- Qualitätsprüfung,
- Klassifikation von Dokumenten oder Anfragen,
- Mustererkennung in großen Datenmengen,
- Optimierung von Prozessen,
- datenbasierte Entscheidungsunterstützung.
Entscheidend ist, dass Machine-Learning-Modelle messbar bewertet werden. Genauigkeit, Stabilität, Erklärbarkeit, Laufzeit, Datenabhängigkeit und fachlicher Nutzen müssen regelmäßig geprüft werden.
Qualitätssicherung und Monitoring von KI-Modellen
Ein Machine-Learning-Modell ist nach dem ersten Deployment nicht fertig. Daten verändern sich, Geschäftsprozesse entwickeln sich weiter, Kundenverhalten verschiebt sich und technische Rahmenbedingungen ändern sich. Deshalb brauchen KI-Modelle kontinuierliche Qualitätssicherung, Monitoring und Wartung.
Ohne Monitoring kann die Modellqualität unbemerkt sinken. Ein Modell, das zu Beginn gute Ergebnisse liefert, kann später schlechter werden, wenn sich Datenverteilungen verändern oder neue Muster entstehen. Dieses Phänomen wird häufig als Model Drift oder Data Drift beschrieben. Unternehmen müssen deshalb beobachten, ob die Ergebnisse weiterhin zuverlässig sind.
Qualitätssicherung umfasst nicht nur technische Metriken. Auch fachliche Bewertung, Plausibilitätskontrollen, Fehleranalyse, Dokumentation und Feedback aus dem Betrieb sind wichtig. Bei produktiven KI-Anwendungen sollte klar sein, wann ein Modell angepasst, neu trainiert oder ersetzt werden muss.
Wichtige Aspekte der Qualitätssicherung sind:
- Validierung mit geeigneten Testdaten,
- Überwachung der Modellperformance,
- Erkennung von Datenveränderungen,
- regelmäßige fachliche Prüfung der Ergebnisse,
- Dokumentation von Modellversionen,
- Monitoring im produktiven Betrieb,
- klare Prozesse für Anpassung und Retraining,
- Bewertung von Risiken und Fehlentscheidungen.
So bleibt Künstliche Intelligenz nicht nur ein einmaliges Projekt, sondern wird zu einer dauerhaft verlässlichen Fähigkeit im Unternehmen. Unternehmen können produktive KI-Modelle langfristig betreuen lassen, Monitoring und Retraining beauftragen, Wartung buchen oder technischen Service anfragen.
Integration von KI und Daten in bestehende Prozesse
Data & AI Solutions entfalten ihren Wert erst dann vollständig, wenn sie in bestehende Unternehmensprozesse integriert werden. Ein Dashboard, ein Machine-Learning-Modell oder eine KI-Analyse ist nur dann nützlich, wenn die Ergebnisse dort verfügbar sind, wo Entscheidungen getroffen oder Prozesse gesteuert werden.
Das kann in Fachanwendungen, Portalen, CRM-Systemen, ERP-Systemen, Serviceplattformen oder individuellen Softwarelösungen geschehen. Je nach Use Case können Ergebnisse automatisch weiterverarbeitet, als Empfehlung angezeigt, in Workflows integriert oder für Management-Reports genutzt werden.
Eine erfolgreiche Integration berücksichtigt sowohl technische als auch organisatorische Aspekte. Systeme müssen miteinander kommunizieren können, Datenflüsse müssen stabil sein, Zugriffsrechte müssen passen und Mitarbeitende müssen verstehen, wie die Ergebnisse verwendet werden sollen.
Typische Integrationsfragen sind:
- In welchem System sollen KI-Ergebnisse sichtbar sein?
- Welche Datenquellen müssen angebunden werden?
- Welche Schnittstellen und APIs sind verfügbar?
- Welche Rollen dürfen welche Daten sehen?
- Wie werden Ergebnisse dokumentiert?
- Wo braucht es menschliche Prüfung oder Freigabe?
- Wie wird die Lösung im Betrieb überwacht?
Ancud IT betrachtet Künstliche Intelligenz und Daten deshalb immer im Zusammenhang mit Softwareentwicklung, Datenarchitektur, Prozessautomatisierung und Systemintegration. Unternehmen können eine KI-Integration beauftragen, Datenflüsse umsetzen lassen oder datenbasierte Funktionen in bestehende Systeme einführen lassen.
KI-Datenanalyse als Wettbewerbsvorteil
Unternehmen, die ihre Daten besser verstehen, können schneller und präziser handeln. KI-Datenanalyse hilft, Muster sichtbar zu machen, Zusammenhänge zu erkennen und Entscheidungen auf eine belastbarere Grundlage zu stellen. Dadurch entstehen Wettbewerbsvorteile in Bereichen wie Vertrieb, Kundenservice, Produktion, Logistik, Qualitätsmanagement, Controlling und Produktentwicklung.
Der Mehrwert liegt nicht nur in automatisierten Analysen. Unternehmen gewinnen auch ein besseres Verständnis für ihre eigenen Abläufe. Welche Kunden verhalten sich ähnlich? Welche Prozesse verursachen Aufwand? Wo entstehen Qualitätsprobleme? Welche Faktoren beeinflussen Nachfrage, Kosten oder Servicequalität? Welche Entscheidungen können durch Daten objektiver getroffen werden?
KI-Datenanalyse kann dabei helfen, operative Effizienz zu steigern, Risiken früher zu erkennen und neue Geschäftspotenziale zu identifizieren. Wichtig ist, dass die Ergebnisse verständlich aufbereitet werden. Fachbereiche müssen nachvollziehen können, was analysiert wurde und wie die Ergebnisse verwendet werden sollen.
Typische Vorteile von KI-Datenanalyse sind:
- bessere Entscheidungsgrundlagen,
- schnellere Auswertung großer Datenmengen,
- Erkennung verborgener Muster,
- präzisere Prognosen,
- Optimierung von Prozessen,
- bessere Kunden- und Marktanalyse,
- Unterstützung bei Qualitätsmanagement und Controlling,
- Grundlage für neue digitale Services.
So wird aus Künstlicher Intelligenz und Daten ein praktischer Hebel für messbare Geschäftsergebnisse. Unternehmen können eine KI-Datenanalyse anfragen, Predictive Analytics beauftragen oder eine datenbasierte Lösung für Vertrieb, Service, Produktion, Logistik oder Qualitätsmanagement umsetzen lassen.
KI-Datenanalyse, Predictive Analytics und Machine Learning in der Praxis
Künstliche Intelligenz und Daten werden für Unternehmen besonders wertvoll, wenn aus vorhandenen Informationen konkrete Analysen, Prognosen und Handlungsempfehlungen entstehen. Genau hier greifen KI-Datenanalyse, Data Science und Machine Learning ineinander. Während klassische Auswertungen vor allem beschreiben, was passiert ist, können Machine-Learning-Modelle Muster erkennen, Entwicklungen vorhersagen und komplexe Zusammenhänge in Daten sichtbar machen.
Data Science und künstliche Intelligenz helfen Unternehmen dabei, große Datenmengen nicht nur zu sammeln, sondern geschäftlich nutzbar zu machen. Dazu gehören statistische Analysen, Data Analytics mit künstlicher Intelligenz, Predictive Analytics, Deep Learning und die Entwicklung produktiver Machine-Learning-Modelle. Wichtig ist dabei immer der konkrete Use Case: Welche Frage soll beantwortet werden? Welche Daten sind verfügbar? Welche Entscheidung soll durch die Analyse besser werden?
Typische Anwendungsgebiete für KI-Datenanalyse und Machine Learning sind zum Beispiel:
- Predictive Analytics zur Vorhersage von Nachfrage, Verhalten oder Risiken,
- KI-gestützte Textanalyse für Dokumente, Tickets, Feedback oder Serviceanfragen,
- Bilderkennung mit KI und künstliche Intelligenz in der Bildverarbeitung,
- Anomalieerkennung in Prozessen, Datenströmen oder technischen Systemen,
- Kundensegmentierung und datenbasierte Personalisierung,
- Qualitätsprüfung und Mustererkennung in Produktions- oder Prozessdaten,
- Prognosen für Controlling, Planung und operative Steuerung.
Auch Deep Learning kann sinnvoll sein, wenn sehr große Datenmengen, komplexe Muster oder unstrukturierte Daten wie Bilder, Texte oder Sensordaten verarbeitet werden müssen. Nicht jeder Use Case benötigt jedoch Deep Learning. Häufig sind klassische Machine-Learning-Modelle, statistische Verfahren oder Business-Intelligence-Ansätze schneller, transparenter und wirtschaftlich sinnvoller.
Für erfolgreiche KI-Projekte sind Trainingsdaten entscheidend. Trainingsdaten für KI müssen fachlich relevant, sauber strukturiert und ausreichend repräsentativ sein. Wenn die Datenbasis nicht zur Fragestellung passt, entstehen auch mit modernen Algorithmen keine belastbaren Ergebnisse. Deshalb bewertet Ancud IT nicht nur die technische Machbarkeit, sondern auch Datenqualität, Datenverfügbarkeit, Modellrisiken und den konkreten geschäftlichen Nutzen.
So entsteht ein pragmatischer Ansatz für Künstliche Intelligenz, Machine Learning und Data Analytics: nicht Technologie um der Technologie willen, sondern datenbasierte Lösungen, die bessere Entscheidungen ermöglichen, Prozesse optimieren und neue digitale Geschäftsmodelle unterstützen.
Data & AI Solutions mit Ancud IT
Ancud IT unterstützt Unternehmen dabei, Daten und Künstliche Intelligenz strategisch und technisch sinnvoll zu nutzen. Unternehmen können eine Data-&-AI-Beratung beauftragen, einen Use Case anfragen, Datenpipelines entwickeln lassen, Machine-Learning-Modelle umsetzen lassen und produktive Lösungen sicher einführen. Von der ersten Use-Case-Bewertung über Data Engineering, Business Intelligence und Machine-Learning-Modelle bis hin zu Deployment, Monitoring und Wartung begleiten wir den gesamten Lebenszyklus datengetriebener Lösungen.
Unser Ansatz verbindet technologische Erfahrung mit einem klaren Blick auf den geschäftlichen Nutzen. Wir entwickeln keine isolierten KI-Demos, sondern Lösungen, die in bestehende IT-Landschaften, Prozesse und Entscheidungswege passen. Dabei berücksichtigen wir Datenqualität, Skalierbarkeit, Governance, Integration und langfristige Wartbarkeit.
Ob Unternehmen ihre Dateninfrastruktur verbessern, BI-Lösungen aufbauen, Machine-Learning-Modelle entwickeln oder KI-Datenanalyse produktiv einsetzen möchten: Entscheidend ist ein strukturierter Weg von der Datenbasis bis zur nutzbaren Anwendung.
Künstliche Intelligenz und Daten werden dann wertvoll, wenn sie Orientierung schaffen, Prozesse verbessern und Entscheidungen unterstützen. Genau dabei hilft Ancud IT: mit Data & AI Solutions, die technisch belastbar, fachlich sinnvoll und auf nachhaltige Wirkung im Unternehmen ausgerichtet sind.
Data & AI Beratung: Preise und Kosten transparent kalkulieren
Der Preis für ein Data-&-AI-Projekt hängt von der Datenlage, dem gewünschten Use Case, der Anzahl anzubindender Systeme, der technischen Architektur und dem erforderlichen Automatisierungsgrad ab. Die Preise unterscheiden sich deshalb je nachdem, ob zunächst nur eine Datenevaluierung, ein Dashboard, eine Datenpipeline, ein Proof of Concept oder eine produktive KI-Lösung umgesetzt werden soll. Zu den Kosten können Beratung, Data Engineering, Modellentwicklung, Schnittstellen, Deployment, Qualitätssicherung, Monitoring und Wartung gehören.
Ein verbindlicher Preis lässt sich nach einer ersten Analyse deutlich zuverlässiger bestimmen. Unsere Preise orientieren sich am konkreten Projektumfang und werden in einem individuellen Angebot transparent dargestellt. So können Unternehmen die erwarteten Kosten für Data Engineering, Business Intelligence, Machine Learning, KI-Datenanalyse und langfristige Betreuung realistisch vergleichen und schrittweise planen.
Ob Sie eine Data-&-AI-Beratung beauftragen, einen Data Readiness Check bestellen, eine Datenpipeline entwickeln lassen, ein Machine-Learning-Modell umsetzen lassen, eine BI-Lösung einführen, produktive Modelle betreuen lassen, Wartung buchen oder technischen Service anfragen möchten: Über die Kontaktseite können Sie Ihr Vorhaben unverbindlich anfragen und ein individuelles Angebot erhalten.
CRISP-ML
Nutzen Sie wertvolle Daten zu Ihrem Vorteil
Die erfolgreiche Umsetzung von KI-Modellen geht mit vielen ineinandergreifenden Komponenten und Prozessen einher.
Der Industriestandard CRISP (Cross-Industry Standard Process) bietet ein systematisches Prozessmodell für die Entwicklung von Machine-Learning-Anwendungen, das mögliche Risiken minimiert und die Qualitätssicherung betont. Deshalb bieten wir alle Komponenten des CRISP-Modells an, das alle Phasen vom Projektentwurf bis zur Realisierung einer Machine-Learning-Anwendung abdeckt. So stellen wir den Erfolg Ihrer Machine-Learning-Projekte auf allen Ebenen sicher.
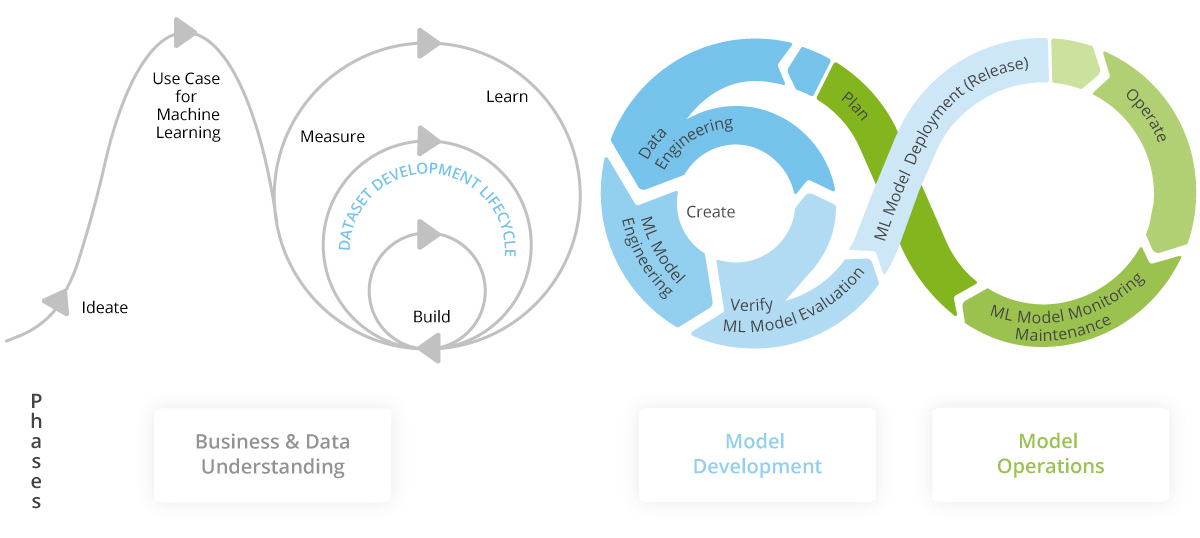
Unsere Services nach dem CRISP-Modell

Data Engineering
Wir bereiten Daten gezielt auf, sodass sie als belastbare Grundlage für die Modellierungsphase dienen.

Use Case und Datenevaluierung
Wir definieren den Projektumfang und Erfolgskriterien und prüfen die Daten systematisch auf Qualität und Eignung.

Modellentwicklung
Wir analysieren und bewerten geeignete Machine-Learning-Modelle für den jeweiligen Anwendungsfall.

Qualitätssicherung
Wir validieren das Modell anhand geeigneter Testdaten, um verlässliche Ergebnisse sicherzustellen.

Deployment
Wir integrieren das trainierte Modell in den zuvor definierten Use Case.

Überwachung und Wartung
Wir überwachen die Modellqualität kontinuierlich und optimieren sie bei Bedarf.
Business Intelligence
Business Intelligence (BI) ist ein Bereich der Unternehmensführung, der sich mit der Sammlung, Analyse und Präsentation von Daten befasst. Dabei werden neben der grafischen Darstellung aussagekräftige KPIs definiert, die der Entscheidungsfindung dienen und Geschäftsprozesse optimieren. Durch die effektive Nutzung von BI-Tools können Unternehmen wettbewerbsfähiger werden, ihre Kunden oder Prozesse besser verstehen und ihre Effizienz steigern. Die Bedeutung von BI wird in Zukunft weiter zunehmen, da Unternehmen zunehmend auf datenbasierte Entscheidungen angewiesen sind.
2023 Gartner Top Strategic Technology Trends: Detailed Guide (eBook)
Auf dem Weg zu Ihrer maßgeschneiderten BI Lösung kümmert sich unser interdisziplinäres Team aus Data Engineers und Data Scientists um die

Dateninfrastruktur (siehe auch Data Engineering)

Statistische Datenanalyse und KPI Evaluation

Grafische Darstellung mithilfe von Dashboards

Microsoft Power BI, ein starkes Visualisierungstool für alle Microsoft User
Unsere Use Cases

KI-LiDAR
Erfahren Sie, wie unsere innovative Technologie der künstlichen Intelligenz mit miniaturisierten LiDAR-Sensoren und fortschrittlicher Datenfusion die Sicherheit und Zuverlässigkeit autonomer Fahrzeuge verändert – nicht nur im Bereich des autonomen Fahrens, sondern auch in den Bereichen Robotik, Industrieautomation, Luft- und Raumfahrt, Sicherheit und Überwachung.
Informieren Sie sich im persönlichen Austausch
Sie möchten die Vorteile von KI-Lösungen nutzen, um Ihr Unternehmen weiter zu bringen?
Kommen Sie auf uns zu – wir beraten Sie gerne über Möglichkeiten und Anforderungen, damit Sie so schnell wie möglich auf die Überholspur kommen!

Häufige Fragen zu Künstlicher Intelligenz, Daten und Machine Learning
KI-Datenanalyse verbindet klassische Datenanalyse mit Methoden der künstlichen Intelligenz und des Machine Learning. Unternehmen können damit große Datenmengen auswerten, Muster erkennen, Zusammenhänge sichtbar machen und bessere Entscheidungen vorbereiten. Besonders relevant ist KI-Datenanalyse, wenn vorhandene Unternehmensdaten nicht nur dokumentiert, sondern aktiv für Prognosen, Optimierung und datenbasierte Steuerung genutzt werden sollen.
Data Science beschäftigt sich mit der Analyse, Strukturierung und Interpretation von Daten. Künstliche Intelligenz erweitert diesen Ansatz, indem KI-Modelle Muster erkennen, Prognosen erstellen oder Entscheidungen unterstützen können. Für Unternehmen ist die Kombination aus Data Science und künstlicher Intelligenz besonders wertvoll, wenn aus Daten konkrete Handlungsempfehlungen, Prozessverbesserungen oder neue digitale Services entstehen sollen.
Künstliche Intelligenz ist der Oberbegriff für Systeme, die Aufgaben übernehmen, die normalerweise menschliche Intelligenz erfordern. Machine Learning ist ein Teilbereich der künstlichen Intelligenz und nutzt Daten, um Modelle zu trainieren und Muster zu erkennen. Deep Learning ist wiederum ein spezieller Bereich des Machine Learning, der mit neuronalen Netzen arbeitet und besonders bei großen Datenmengen, Textanalyse, Bilderkennung und komplexer Mustererkennung eingesetzt wird.
Machine Learning lohnt sich, wenn Unternehmen vorhandene Daten nutzen möchten, um Muster zu erkennen, Prognosen zu erstellen oder Entscheidungen datenbasiert zu unterstützen. Typische Anwendungsbeispiele für Machine Learning sind Nachfrageprognosen, Anomalieerkennung, Kundensegmentierung, Qualitätsprüfung, Dokumentenklassifikation und Prozessoptimierung. Wichtig ist, dass ausreichend relevante Daten vorhanden sind und der konkrete geschäftliche Nutzen klar definiert wird.
Trainingsdaten sind die Grundlage für Machine-Learning-Modelle. Sie bestimmen, welche Muster ein Modell lernen kann und wie zuverlässig die späteren Ergebnisse sind. Für erfolgreiche KI-Projekte müssen Trainingsdaten vollständig, aktuell, relevant und fachlich geeignet sein. Schlechte oder einseitige Trainingsdaten können dazu führen, dass KI-Modelle ungenaue, verzerrte oder nicht nutzbare Ergebnisse liefern.
Predictive Analytics nutzt Daten, Statistik und Machine Learning, um zukünftige Entwicklungen besser einzuschätzen. Unternehmen können damit zum Beispiel Nachfrage, Kundenverhalten, Risiken, Wartungsbedarf, Prozessengpässe oder Qualitätsabweichungen prognostizieren. Künstliche Intelligenz hilft dabei, Muster in historischen Daten zu erkennen und daraus Vorhersagen für bessere Entscheidungen abzuleiten.
Künstliche Intelligenz kann in der Textanalyse eingesetzt werden, um Dokumente, Tickets, E-Mails, Kundenfeedback, Serviceanfragen oder Verträge automatisch auszuwerten. KI-gestützte Textanalyse kann Inhalte klassifizieren, zusammenfassen, relevante Informationen extrahieren und große Textmengen schneller durchsuchbar machen. Das ist besonders hilfreich für Kundenservice, Wissensmanagement, Dokumentenverarbeitung und interne Rechercheprozesse.
Bilderkennung mit KI nutzt Machine Learning oder Deep Learning, um Objekte, Muster, Qualitätsmerkmale oder Abweichungen in visuellen Daten zu erkennen. Künstliche Intelligenz in der Bildverarbeitung kann zum Beispiel in Qualitätssicherung, Produktion, Logistik, technischer Prüfung oder Dokumentenverarbeitung eingesetzt werden. Entscheidend ist, dass passende Bilddaten vorhanden sind und das Modell für den konkreten Anwendungsfall trainiert und validiert wird.
Business Intelligence macht vorhandene Daten durch Reports, Kennzahlen und Dashboards verständlich. Künstliche Intelligenz und Machine Learning erweitern diese Grundlage um Mustererkennung, Prognosen und automatisierte Analysen. Für Unternehmen ergänzen sich Business Intelligence und künstliche Intelligenz: BI schafft Transparenz, während KI zusätzliche Erkenntnisse, Vorhersagen und Optimierungsmöglichkeiten liefern kann.
Data Analytics beschreibt die Auswertung von Daten, um Entwicklungen, Zusammenhänge und Kennzahlen sichtbar zu machen. Künstliche Intelligenz geht darüber hinaus, indem Modelle aus Daten lernen, Muster erkennen und Prognosen oder Empfehlungen erstellen können. In vielen Projekten greifen Data Analytics und künstliche Intelligenz ineinander: Zuerst werden Daten verstanden und strukturiert, danach können Machine-Learning-Modelle oder KI-Anwendungen entwickelt werden.
Typische KI-Anwendungsgebiete für Unternehmen sind KI-Datenanalyse, Predictive Analytics, Machine-Learning-Modelle, Business Intelligence, Textanalyse, Bilderkennung, Qualitätsprüfung, Kundenanalyse, Prozessoptimierung und datenbasierte Entscheidungsunterstützung. Besonders sinnvoll ist künstliche Intelligenz dort, wo viele Daten entstehen, wiederkehrende Entscheidungen vorbereitet werden müssen oder komplexe Muster manuell schwer erkennbar sind.
Praktische Machine-Learning-Anwendungsbeispiele sind Nachfrageprognosen, Churn-Analysen, Betrugserkennung, Anomalieerkennung, Produktempfehlungen, Dokumentenklassifikation, Qualitätskontrolle, Bilderkennung, Textanalyse und intelligente Prozessoptimierung. Unternehmen können Machine Learning sowohl für operative Prozesse als auch für strategische Entscheidungen einsetzen, wenn Datenqualität, Use Case und Integration in bestehende Systeme zusammenpassen.
Data Engineering ist eine zentrale Voraussetzung für erfolgreiche KI-Projekte. Daten müssen aus verschiedenen Quellen integriert, bereinigt, transformiert und für Analysen oder Machine-Learning-Modelle bereitgestellt werden. Ohne Data Engineering bleiben viele Daten isoliert oder unbrauchbar. Eine saubere Datenbasis ist deshalb entscheidend für KI-Datenanalyse, Business Intelligence, Predictive Analytics und produktive Data & AI Solutions.
CRISP-ML ist ein strukturiertes Vorgehensmodell für Machine-Learning-Projekte. Es hilft Unternehmen, KI-Projekte von der Use-Case-Definition über Datenevaluierung, Data Engineering, Modellentwicklung und Qualitätssicherung bis hin zu Deployment, Monitoring und Wartung methodisch umzusetzen. Dadurch werden KI-Projekte planbarer, nachvollziehbarer und besser in den produktiven Betrieb überführbar.
Machine-Learning-Modelle müssen überwacht werden, weil sich Daten, Prozesse und Rahmenbedingungen im Unternehmen verändern können. Ein Modell, das zu Beginn gute Ergebnisse liefert, kann mit der Zeit an Qualität verlieren. Monitoring hilft, Data Drift, Model Drift, fehlerhafte Ergebnisse oder sinkende Modellperformance frühzeitig zu erkennen. Dadurch bleiben KI-Anwendungen langfristig zuverlässig und nutzbar.
Ein guter Einstieg beginnt mit der Bewertung von Datenlage, Geschäftsproblem und möglichem Nutzen. Unternehmen sollten prüfen, welche Daten vorhanden sind, welche Prozesse verbessert werden können und ob Business Intelligence, Data Engineering, Machine Learning oder KI-Datenanalyse der passende Ansatz ist. Danach können konkrete Use Cases priorisiert und schrittweise in produktive Data & AI Solutions überführt werden.