Data Engineering
Strukturierte Datenbasis für leistungsfähige KI-Systeme
Vor der Datenanalyse und Modellierung müssen Ihre Daten aufbereitet werden. Dazu gehören insbesondere:
Datenauswahl
Selektion und Bereitstellung der für die Analyse oder Modellierung notwendigen Daten.
Datenbereinigung
Durchführung von Fehlererkennungs- und Fehlerkorrekturschritten, z. B. für fehlerhafte Daten, fehlende Werte oder einzelne Datenpunkte.
Datenstandardisierung
Vereinheitlichung von Eingabedaten für Machine-Learning-Tools, um das Risiko fehlerhafter Eingabedaten zu reduzieren.
Weiterlesen
Data Engineering Consulting für Unternehmen
Data Engineering schafft die technische Grundlage, damit Datenanalyse, Business Intelligence, Machine Learning und KI-Systeme zuverlässig funktionieren. Unternehmen verfügen häufig über viele Datenquellen, aber erst durch Datenintegration, Datenbereinigung, Datenstandardisierung und stabile Data Pipelines entsteht eine belastbare Datenbasis. Ancud IT unterstützt beim Aufbau moderner Dateninfrastrukturen – von der ersten Analyse bis zur produktiven Datenplattform.
Warum Data Engineering für KI-Systeme wichtig ist
KI-Modelle und Machine-Learning-Anwendungen sind nur so gut wie die Daten, auf denen sie basieren. Deshalb beginnt ein erfolgreiches KI-Projekt nicht beim Modell, sondern bei der Qualität, Struktur und Verfügbarkeit der Daten. Data Engineering verbindet technische Architektur mit fachlichem Datenverständnis und macht Daten aus unterschiedlichen Quellen für Analyse, Modellierung und Automatisierung nutzbar.
- Auswahl relevanter Datenquellen für Analyse und Modellierung
- Datenbereinigung, Validierung und Standardisierung
- Aufbau von Data Pipelines, ETL- und ELT-Prozessen
- Bereitstellung skalierbarer Dateninfrastruktur für KI- und Data-Science-Projekte
Data Pipelines, ETL und Monitoring
Professionelle Data Pipelines automatisieren den Datenfluss zwischen Quellsystemen, Speicherlösungen, Analysewerkzeugen und Machine-Learning-Umgebungen. Dabei geht es nicht nur um das reine Kopieren von Daten, sondern um Orchestrierung, Transformation, Fehlerbehandlung und Monitoring. Tools wie Apache Airflow helfen, ETL-Jobs zu planen, Abhängigkeiten sichtbar zu machen und Datenprozesse nachvollziehbar zu betreiben.
- Datenquellen identifizieren und anbinden
- Daten extrahieren, transformieren und validieren
- Daten in Data Lake, Data Warehouse oder Analyseplattform bereitstellen
- Pipelines überwachen, Fehler erkennen und Datenqualität sichern
Data Lake, Data Stack und Dateninfrastruktur
Ein Data Lake oder ein passender Data Stack bündelt Rohdaten, strukturierte Daten, Dateien, Bilder, JSON-Daten, CSV-Dateien und Datenbankinhalte in einer technischen Architektur. Je nach Anforderungen kann diese Infrastruktur in der Cloud, on-premises oder hybrid umgesetzt werden. Für sensible Daten oder spezielle Betriebsmodelle kann ein On-Premises Data Lake mit Komponenten wie MinIO, Kubernetes und eigenen Servern sinnvoll sein.
- Data Lake und Storage Layer für Data-Science-Projekte
- Data Warehouse oder Lakehouse für Reporting und Analytics
- Cloud-, Hybrid- oder On-Premises-Architektur
- Integration mit Cloud Migration, AWS Consulting Services und bestehenden Unternehmenssystemen
Change Data Capture mit Debezium und Kafka
Change Data Capture macht Datenbankänderungen für moderne Datenarchitekturen nutzbar. Mit Debezium und Kafka lassen sich Transaktionen, Änderungen und Ereignisse nahezu in Echtzeit erfassen und in nachgelagerte Systeme übertragen. Dadurch entstehen Streaming Data Pipelines für Reporting, Datenintegration, Synchronisation, Event-basierte Anwendungen und KI-nahe Datenverarbeitung.
Data Engineering für Machine Learning und Computer Vision
Für Machine Learning, Computer Vision und andere Data & AI Solutions müssen Daten in einer Form vorliegen, die Modelle effizient verarbeiten können. Dazu gehören Trainingsdaten, Bilddaten, strukturierte Tabellen, Metadaten und geeignete Feature-Sets. Data Engineering sorgt dafür, dass diese Daten korrekt, konsistent und wiederverwendbar bereitstehen – beispielsweise für CNN-Modelle, TensorFlow, Keras oder individuelle KI-Lösungen.
Data Engineering mit Ancud IT
Ancud IT begleitet Unternehmen beim Data Engineering Consulting, beim Aufbau von Data Pipelines, Data Lakes, Data Stacks und datengetriebenen Architekturen. Der Fokus liegt auf einer belastbaren Datenbasis, die Analyse, Reporting, KI-Beratung, Machine Learning und produktive KI-Systeme unterstützt. So werden aus verteilten Datenquellen nutzbare Informationen und aus Datenprojekten stabile technische Lösungen.
Mit unseren Data-Engineering-Tools stellen wir zuverlässige Datenströme aus unterschiedlichsten Quellen bereit und schaffen die nötige Infrastruktur für den optimalen Workflow Ihres Data-Science-Projekts:
In unserem Team beschäftigen wir uns ständig mit den neuesten Technologien, um maßgeschneiderte Lösungen für möglichst viele Use Cases in modernen datengetriebenen Projekten zu bieten. In den folgenden Medium-Artikeln zeigen wir Schritt für Schritt mögliche Umsetzungen auf Basis unserer technischen Expertise:
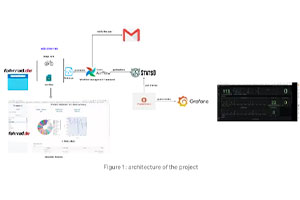
Data Pipelines with Monitoring Tools
Schritt-für-Schritt-Anleitung für den Aufbau eines Data Stacks
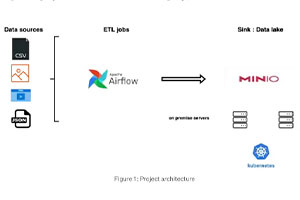
On Premises Data Lake
Erstellung eines Storage Layers für jedes Data-Science-Projekt in einer On-Premises-Konfiguration
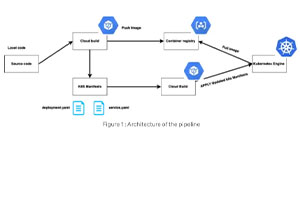
Computer Vision from Scratch
Aufbau eines CNN-Modells mit Tensorflow und Keras
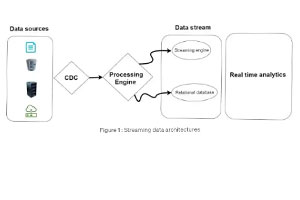
Change Data Capture using Debezium Kafka
Nutzung von Debezium, um Änderungen und Transaktionen bei der Nutzung von Datenbanken zu erfassen
Häufige Fragen zu Data Engineering
Data Engineering umfasst die technische Aufbereitung, Integration, Speicherung und Bereitstellung von Daten. Ziel ist eine stabile Datenbasis für Analyse, Reporting, Machine Learning und KI-Systeme. Ancud IT unterstützt Unternehmen beim Aufbau passender Datenarchitekturen und Data Pipelines.
KI-Systeme benötigen qualitativ hochwertige, konsistente und verfügbare Daten. Ohne Datenbereinigung, Standardisierung und zuverlässige Pipelines entstehen fehlerhafte Ergebnisse oder instabile Modelle. Data Engineering stellt sicher, dass Daten für Data & AI Solutions technisch nutzbar sind.
Zur Datenaufbereitung gehören Datenauswahl, Datenbereinigung, Datenstandardisierung, Validierung und die Bereitstellung geeigneter Datenformate. Außerdem werden Fehler, fehlende Werte, Dubletten und uneinheitliche Strukturen korrigiert, damit Daten in Analyse- und Machine-Learning-Tools verwendet werden können.
Datenbereinigung entfernt oder korrigiert fehlerhafte, unvollständige oder widersprüchliche Daten. Datenstandardisierung vereinheitlicht Formate, Bezeichnungen, Einheiten und Strukturen. Beide Schritte sind wichtig, um Datenqualität und Vergleichbarkeit sicherzustellen.
Eine Data Pipeline ist ein automatisierter Datenfluss von einer oder mehreren Quellen zu Zielsystemen wie Data Lake, Data Warehouse, Analyseplattform oder Machine-Learning-Umgebung. Sie extrahiert, transformiert, validiert und überträgt Daten regelmäßig oder nahezu in Echtzeit.
Apache Airflow wird häufig genutzt, um ETL-Jobs und Datenprozesse zu orchestrieren. Damit lassen sich Abhängigkeiten, Zeitpläne, Fehlerbehandlung und Monitoring von Data Pipelines strukturiert abbilden. Das ist besonders hilfreich bei komplexen Data Stacks und wiederkehrenden Datenverarbeitungen.
Ein Data Lake ist eine Speicherarchitektur, in der große Mengen strukturierter und unstrukturierter Daten gesammelt werden. Dazu können Tabellen, Dateien, Bilder, JSON-Daten, CSV-Dateien oder Datenbankexporte gehören. Ein Data Lake dient häufig als Grundlage für Data Science, Reporting und KI-Anwendungen.
Ein On-Premises Data Lake kann sinnvoll sein, wenn Daten aus Sicherheits-, Datenschutz-, Compliance- oder Performance-Gründen intern verarbeitet werden sollen. Unternehmen behalten damit mehr Kontrolle über Infrastruktur, Speicherorte und Zugriffe. Je nach Projekt können auch hybride Architekturen mit Cloud-Komponenten sinnvoll sein.
Change Data Capture erfasst Änderungen in Datenbanken und überträgt sie an andere Systeme. Mit Debezium und Kafka können Transaktionen nahezu in Echtzeit als Events verarbeitet werden. Das eignet sich für Streaming Data Pipelines, Synchronisation, Reporting und datengetriebene Anwendungen.
Data Engineering bereitet Trainingsdaten, Bilddaten, Tabellen, Metadaten und Feature-Sets so auf, dass Machine-Learning-Modelle und Computer-Vision-Anwendungen zuverlässig damit arbeiten können. Dadurch werden Modelltraining, Validierung und produktiver Betrieb deutlich stabiler.
Data Engineering verbessert die Datenqualität durch Validierung, Fehlererkennung, Bereinigung, Standardisierung, Monitoring und klare Datenflüsse. So lassen sich fehlerhafte Datenpunkte, inkonsistente Formate und unzuverlässige Datenquellen frühzeitig erkennen und korrigieren.
Ancud IT unterstützt beim Aufbau von Data Pipelines, Data Lakes, Data Stacks und Datenarchitekturen. Dazu gehören Beratung, technische Konzeption, Implementierung, Integration bestehender Systeme und die Vorbereitung von Daten für Reporting, Data Science, Machine Learning und GenAI-Anwendungen.
Machen Sie den ersten Schritt
Unabhängig davon, inwieweit Ihre Daten aufbereitet werden müssen, finden wir die passende Lösung ganz nach Ihren Bedürfnissen.
Lassen Sie sich von uns unverbindlich beraten, durch unsere jahrelange Expertise unterstützen wir Sie dabei, Ihre Daten für Ihre weiteren Schritte aufzubereiten.
